2026년 03월 26일
사용자가 페이지 로딩을 눈치채지 못하게 만들기
- 블로그 상세 페이지 RSC 적용기
최적화
Next.js App Router에서 RSC와 Tanstack Query로 LCP 개선하기
1. 도입배경
이번 글에서는 Next.js App Router 환경에서 RSC (React Server Component) 와 Tanstack Query의 HydrationBoundary 를 활용하여 블로그 상세 페이지의 초기 렌더링 경험을 개선한 과정을 정리해보려고 합니다.
서비스를 운영하는 개발자라면 누구나 사용자가 불편함을 느끼지 않도록 페이지 진입 속도를 최적화하고, 단 0.1초라도 더 빠르게 화면을 구성하려는 목표를 갖고 있을 것입니다.
비즈니스 관점에서도 페이지가 빠르면 사용자는 자연스럽게 더 많은 콘텐츠를 소비하고 사이트에 오래 머무르게 됩니다. 반대로 렌더링이 1초 지연될 때마다 사용자 이탈률은 급격히 상승합니다. 블로그 상세 페이지는 콘텐츠 자체가 핵심인 만큼, 어떻게 하면 가장 핵심인 본문 영역을 흔들림 없이 즉시 보여줄 수 있을까? 라는 고민에서 개선을 시작했습니다.
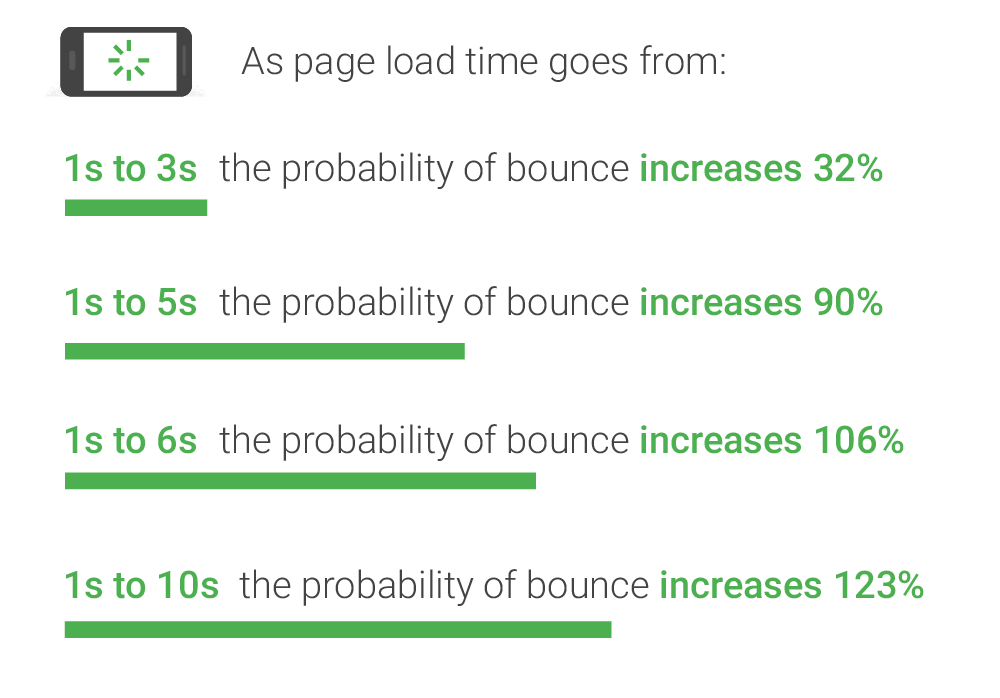
2. 문제 상황 정의: 클라이언트 페칭의 한계와 UX 손실
기존의 방식은 상세 페이지의 주요 데이터를 클라이언트 컴포넌트에서 가져왔습니다. 하지만 Tanstack Query를 클라이언트에서만 사용할경우 필연적으로 다음과 같은 흐름을 겪게 됩니다.
'use client'의 제약: useQuery는 클라이언트 훅이므로 반드시클라이언트 컴포넌트내에 위치해야 합니다.- 초기 데이터 공백: 서버에서 HTML이 내려올때 useQuery는 아직 실행 전이므로, 데이터가 없는 isLoading 상태로 첫 화면이 그려집니다.
- UX 손실 경험: 별도 스켈레톤 처리가 없다면 빈 화면이 노출되고, 데이터가 로드된 뒤에야 본문이 채워지며
레이아웃 시프트(Layout Shift)가 발생합니다.
결과적으로 사용자는 페이지가 아직 다 뜨지 않았다는 불안정한 인상을 받게 되며, 이는 서비스 품질에 대한 신뢰도 저하로 이어집니다. 특히 SEO가 중요한 블로그 페이지에서 메타데이터와 핵심 콘텐츠가 서버 단계에서 준비되지 않았다는 점은 큰 약점이었습니다.
3. SSR vs RSC, 무엇이 다른가?
- SSR 전통적인 SSR은 완성된 HTML을 서버에서 렌더링해 전달합니다.
- CSR과의 차이: CSR은 빈
<div id="root"></div>만 먼저 내려받고, JS가 실행될 때까지 기다리지만, SSR은 브라우저가 즉시 레이아웃을 게산할 수 있는 HTML을 전달받습니다. - 한계: FCP(First Contentful Paint)는 개선되지만, 이미지 크기 미지정, 웹 폰트 로딩(FOUT/FOIT), 혹은 Hydration 시점의 차이로 인해 레이아웃 시프트를 완벽히 방지하기는 어렵습니다.
- RSC (React Server Component) 활용
RSC는 SSR과 동일하게 서버에서 동작하지만 렌더링 메커니즘이 완전히 다릅니다. 페이지 전체를 HTML로 만드는 대신, 컴포넌트 자체를 서버에서 실행하고 결과를
RSC Payload형태로 전달합니다.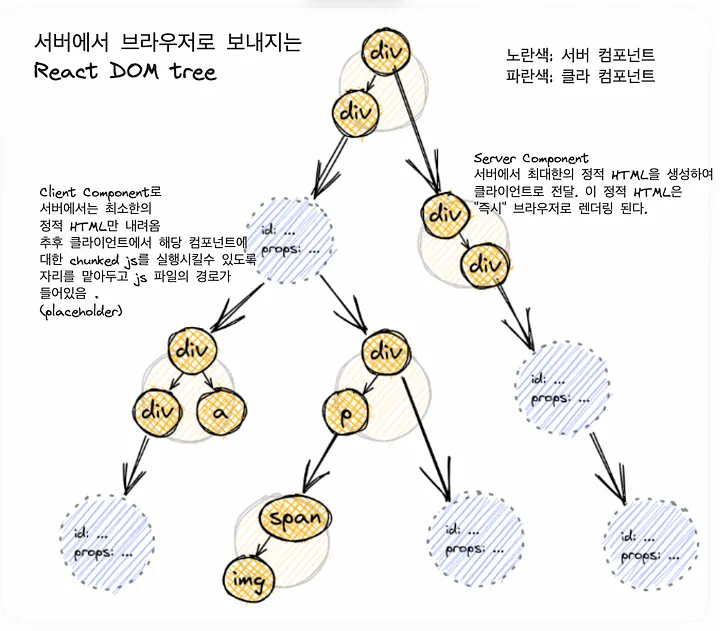
- 서버 동작: 서버는 컴포넌트 트리를 렌더링하여
React Flight Protocol이라는 전용 스트리밍 프로토콜로 직렬화합니다. 이 Payload에는 JSX 결과물, 클라이언트 컴포넌트의 위치(Placeholder), 서버에서 넘겨주는 Props 정보가 담깁니다. - 클라이언트 동작: 브라우저는 전달받은 HTML을 즉시 보여주는 Streaming SSR을 수행합니다.
RSC는 성능 면에서 뛰어나지만, 데이터를 다루는 세부적인 제어(캐싱, 재시도, 선언적 상태 관리 등)를 위해 이미 익숙한 Tanstack Query의 기능을 포기하고 싶지는 않았습니다.
4. 최종 선택: RSC + HydrationBoundary
기존 클라이언트 데이터 계층을 유지하면서 서버의 이점을 극대화하기 위해 RSC와 HydrationBoundary를 조합하는 방식을 선택했습니다.
이 방식의 핵심 시나리오는 서버에서 먼저 조회하고, 클라이언트에서는 이미 캐싱된 데이터를 그대로 활용한다입니다.
실제 구현 방식 서버 컴포넌트인 page.tsx에서 데이터를 미리 fetch하고 queryClient를 통해 데이터를 주입합니다.
1// page.tsx (Server Component) 2const Page = async ({ params }: PageProps<"id">) => { 3 const queryClient = getQueryClient(); 4 const blogId = Number(params.id); 5 6 // 서버에서 데이터 직접 조회 7 const { data } = await useGetDetail(blogId); 8 9 // 서버 측 Query Cache에 데이터 주입 10 queryClient.setQueryData(QUERY_KEYS.BLOG.DETAIL(blogId), data); 11 12 // 캐시 상태를 직렬화(dehydrate) 13 const dehydratedState = dehydrate(queryClient); 14 15 return ( 16 <HydrationBoundary state={dehydratedState}> 17 <Detail blogId={blogId} /> 18 </HydrationBoundary> 19 ); 20};
이렇게 하면 클라이언트 컴포넌트 내의 useQuery는 첫 실행 시 서버에서 미리 채워놓은 캐싱된 데이터를 이용하여 isLoading 상태를 거치지 않고 즉시 데이터를 화면에 그릴 수 있습니다.
5. 개선 결과
이번 개선을 통해 다음과 같은 LCP 개선을 이룰 수 있었습니다.
- LCP (Largest Contentful Paint): 5.1s → 2.4s (약 53% 개선)
- CLS (Cumulative Layout Shift): 0.12 → 0.002 (레이아웃 흔들림 거의 없음)
- FCP (First Contentful Paint): 1.1s → 0.2s
- 초기 데이터 로딩 대기 시간: 1.0s → 0.2s
6. 마무리
단순히 수치상의 개선뿐만 아니라, 실제 체감 속도와 상호작용 반응성이 모두 향상되었으며 이는 곧 UX품질의 향상으로 이어졌습니다. 앞으로도 이러한 성능 최적화 방향을 유지하며 사용자 입장에서 더 빠르고 안정적인 웹 환경을 지속적으로 제공할 계획입니다.
6. 향후 진행
RSC는 공짜가 아니다. 성능과 비용 사이의 선택 RSC 방식은 서버 사이드에서 컴포넌트 단위로 React를 실행하고, 이를 직렬화하여 클라이언트로 전달하기 때문에 일반 CSR 또는 SSR보다 서버 리소스를 상대적으로 더 많이 소모합니다.
특히 RSC는 요청이 발생할 때마다 서버에서 렌더링 로직이 수행되며, 서버에서의 CPU 연산 및 네트워크 I/O 부하가 증가하게 됩니다. 트래픽이 높은 서비스에서는 이러한 부하가 누적되면 서버 스케일링 비용과 응답 지연(latency)문제로 이어질 수 있습니다.
따라서 모든 페이지에 RSC를 일괄 적용하는 것은 비효율적이라고 판단했습니다.
RSC의 주요 장점은 초기 렌더링 속도 개선과 JS 번ㄷ늘 사이즈 감소에 있지만, 모든 페이지가 이 최적화의 우선순위를 필요로 하는 것은 아닙니다. 예를 들어 사용자 진입 빈도가 낮거나, 서버 데이터 의존도가 낮은 정적 페이지는 기존 SSC(Static Site Generation)나 ISR, CSR만으로도 충분히 좋은 성능을 낼 수 있습니다.
이러한 이유로, 서비스 트래픽 데이터를 기반으로 개인 프로젝트 뿐 아니라 실무 코드에서도 선택적으로 적용해볼 수 있는 전략을 개인적으로 수립해볼 수 있었습니다.
구체적으로는 아래와 같은 방식으로 진행해볼 생각입니다.
- 사용자 탐색 데이터 분석
- 내부 로그를 활용해 사용자 진입 빈도와 체류 시간, 전환율이 높은 페이지를 식별합니다.
- 예를 들어 이벤트 상세 페이지나 홈 피드처럼 유입률이 높고, 콘텐츠 노출 속도가 UX에 직접 영향을 주는 영역이 우선 적용 대상이 될 수 있을 것 같습니다.
- RSC 적용 기준 수립
- 서버 렌더링 비용 대비 렌더링 성능 향상 폭을 정량적으로 측정합니다.
- CLS, FCP, TTFB 등의 Web Vitals 지표를 기준으로 개선 효과가 명확한 페이지에만 RSC를 적용합니다.
- 반대로, 정적 데이터 위주의 페이지나 잦은 서버 재요청이 필요없는 페이지는 SSG로 유지합니다.
- 서버 부하 관점의 모니터링 및 점진적 확장
- RSC 적용 후에는 서버 자원 사용량(CPU, 메모리, 응답시간)을 지속적으로 모니터링하며 서버 부하가 임계값을 넘지 않는 선에서 점진적으로 확장 적용할 계획입니다.
- 이를 통해 RSC의 장점을 극대화하면서도 서버 운영 비용을 안정적으로 유지할 수 있습니다.
요약하자면, RSC는 분명히 성능과 사용자 경험 측면에서 강력한 장점을 제공합니다.
그러나 그만큼 서버 자원 소비와 인프라 비용도 함께 늘어나기 때문에, 모든 페이지가 아닌 "렌더링 품질이 직접적인 UX 지표에 영향을 주는 주요 페이지" 중심으로 선택적 적용하는 전략이 가장 현실적이라고 판단했습니다.
이런 접근을 통해 RSC의 장점을 효율적으로 활용하면서도 서비스 안정성과 비용 효율성을 동시에 확보할 수 있을 것입니다.